shared_ptr: the (not always) atomic reference counted smart pointer
Introduction
This is a write-up of the “behavioral analysis” of shared_ptr<T> reference count in GNU’s libstdc++. This smart pointer is used to share references to the same underlaying pointer.
The mechanism beneath works by tracking the amount of references through a reference count so the pointer gets freed only after the last reference is destructed. It is usually used in multi-threaded programs (in conjunction with other types) because of the guarantees of having its reference count tracked atomically.
Story time
A few months ago, I was running a micro-benchmark on data structures in Rust vs C++ ones.
At one point, I found that my Rust port of an immutable RB tree insertion was significantly slower than the C++ one. It was unexpected to me as both codebases were idiomatic and Rustc optimizes very well usually matching C++ speed.
I proceeded to re-check that my code was correct. At first I thought that my re-balancing code could be wrong so I put it side by side with the C++ one but couldn’t find any defect.
Profiling
The second day, I started profiling with callgrind and cachegrind. Here is where I got the aha moment. Every part of the code that was copying shared_ptr<T> was being much faster than my equivalent Arc::clone calls in Rust.
Inside KCachegrind, I saw something unexpected, the code was straightforward but before increasing shared_ptr’s reference count during a pointer copy, there was a branch to decide if it should do an atomic addition or a non-atomic one. The code-path being taken was the non atomic one!
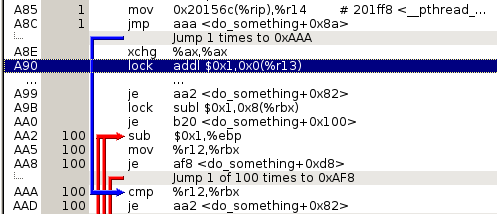
Certainly, my knowledge about shared_ptr was being challenged. As far as I knew, the reference count should be atomic so it could be used in parallel programs sharing the value without the risk of racing the count and ending up with dangling pointers or memory leaks.
Tracking the code
Simplified C++ poc:
const auto tree = make_shared<Tree<int>>(10);
for(auto i = 0; i < 100; i++) {
const shared_ptr<Tree<int>> tree_copy = tree;
// black_box(tree_copy);
}
In Rust it is almost the same line by line:
let tree = Arc::new(Tree::new(10));
for _i in 0..100 {
let tree_copy = tree.clone();
// test::black_box(tree_copy);
}
To understand what was happening better, I compiled the C++ without optimizations which gave me some disassembly to follow:
loop code:
d7b: cmp DWORD PTR [rbp-0x14],0x63
d7f: jg d9a <main+0x59>
d81: lea rdx,[rbp-0x30]
d85: lea rax,[rbp-0x40]
d89: mov rsi,rdx
d8c: mov rdi,rax
d8f: call f1c <std::shared_ptr<Tree<int> >::operator=(std::shared_ptr<Tree<int> > const&)> #### (*)
d94: add DWORD PTR [rbp-0x14],0x1
d98: jmp d7b <main+0x3a>
operator=:
1021: mov rax,QWORD PTR [rbp-0x8]
1025: mov rdi,rax
1028: call 1158 <std::_Sp_counted_base<(__gnu_cxx::_Lock_policy)2>::_M_add_ref_copy()> #### (*)
102d: mov rax,QWORD PTR [rbp-0x18]
1031: mov rax,QWORD PTR [rax]
And following _M_add_ref_copy():
116c: mov esi,0x1
1171: mov rdi,rax
1174: call cfd <__gnu_cxx::__atomic_add_dispatch(int*, int)>
__atomic_add_dispatch:
0000000000000cfd <__gnu_cxx::__atomic_add_dispatch(int*, int)>:
cfd: push rbp
cfe: mov rbp,rsp
d01: sub rsp,0x10
d05: mov QWORD PTR [rbp-0x8],rdi
d09: mov DWORD PTR [rbp-0xc],esi
d0c: call c20 <__gthread_active_p()> #### (1)
d11: test eax,eax
d13: setne al
d16: test al,al
d18: je d2d
d1a: mov edx,DWORD PTR [rbp-0xc]
d1d: mov rax,QWORD PTR [rbp-0x8]
d21: mov esi,edx
d23: mov rdi,rax
d26: call c59 <__gnu_cxx::__atomic_add(int volatile*, int)> #### (2)
d2b: jmp d3e
d2d: mov edx,DWORD PTR [rbp-0xc]
d30: mov rax,QWORD PTR [rbp-0x8]
d34: mov esi,edx
d36: mov rdi,rax
d39: call c9b <__gnu_cxx::__atomic_add_single(int*, int)> #### (3)
d3e: nop
d3f: leave
d40: ret
Once here, I found a very interesting pattern. Depending on the return of __gthread_active_p() (1), it could either call atomic_add (2) or atomic_add_single (3).
atomic_add does what I expect:
c6b: lock add DWORD PTR [rax],edx
but atomic_add_single does not:
caa: mov edx,DWORD PTR [rax]
cac: mov eax,DWORD PTR [rbp-0xc]
caf: add edx,eax
cb1: mov rax,QWORD PTR [rbp-0x8]
cb5: mov DWORD PTR [rax],edx
There are no atomic operations inside that function which opened these new question:
- Why is the C++ standard library optimizing the atomic addition?
- Is this even safe?
To atomic or not to
As expected, atomic_add and atomic_add_single were both straightforward:
static inline void
__atomic_add_single(_Atomic_word* __mem, int __val)
{ *__mem += __val; }
static inline void
__atomic_add(volatile _Atomic_word* __mem, int __val)
{ __atomic_fetch_add(__mem, __val, __ATOMIC_ACQ_REL); }
static inline void
__attribute__ ((__unused__))
__atomic_add_dispatch(_Atomic_word* __mem, int __val)
{
if (__gthread_active_p())
__atomic_add(__mem, __val);
else
__atomic_add_single(__mem, __val);
}
Now the new set of questions were about __gthread_active_p(). After a quick grep, I found that many functions were depending on its return value to go with a thread-safe operation or not. Finding all of them is an exercise for the reader.
To find the right implementation of __gthread_active_p, I preprocessed the file with g++ -E main.cpp and landed on /usr/include/x86_64-linux-gnu/c++/6/bits/gthr-default.h:246:
static __typeof(pthread_key_create) __gthrw___pthread_key_create __attribute__ ((__weakref__("__pthread_key_create")));
static inline int
__gthread_active_p (void)
{
static void *const __gthread_active_ptr
= __extension__ (void *) &__gthrw___pthread_key_create;
return __gthread_active_ptr != 0;
}
weakref and pthread_key_create
__weakref__ is an attribute to declare a weak symbol. It means that if it is referenced in another place, it becomes available, but while it isn’t, it’s a NULL pointer.
It can be used for defining external symbols which may or may not be available. Can also be used for defining functions that could be intercepted by other more specialized ones. There is a blog post with more information about it here.
__pthread_key_create is a function used to assign values into the local thread storage.
I’m sure you have discovered by now what’s happening, but just in case C++ developers left a comment:
For a program to be multi-threaded the only thing that it certainly must be using is pthread_create. However, there may be other libraries that intercept pthread_create with their own definitions to wrap pthreads functionality for some purpose. In those cases, pthread_create being defined might not necessarily mean that libpthread is actually linked in.
For the GNU C library, we can use a known internal name. This is always available in the ABI, but no other library would define it. That is ideal, since any public pthread function might be intercepted just as pthread_create might be. __pthread_key_create is an “internal” implementation symbol, but it is part of the public exported ABI. Also, it’s among the symbols that the static libpthread.a always links in whenever pthread_create is used, so there is no danger of a false negative result in any statically-linked, multi-threaded program.
For others, we choose pthread_cancel as a function that seems unlikely to be redefined by an interceptor library. The bionic (Android) C library does not provide pthread_cancel, so we do use pthread_create there (and interceptor libraries lose).
So basically, what is happening here is checking if pthread_create is being imported into the program. If it is, the weak reference becomes available, otherwise it is NULL. Checking this variable, it is easy to see if the program is using threads or not.
Sound or not
What if a program uses parallelism without bringing pthread_key_create symbol into context? Is it possible?
We can theorize…
Parallelism without pthread
It is possible to create threads by using the OS syscalls bypassing completely the requirement of pthead. (Un)fortunately, I couldn’t find any popular libraries that implement the functionality by using the syscall interface instead of relying on pthread. OpenMP and a few other runtimes I checked all depend on it.
It might exist but doesn’t seem to be very common.
Shared library
Code compiled into a dynamic library can be called from other programs that might introduce external parallelism and expecting the library to be thread-safe because it uses shared_ptr.
To get more into the question, I created an object that doesn’t use pthread_create because it expects all the parallelism to be external. After an objdump of the symbol table I can see that the symbol is still imported as weak (the w in the second column):
0000000000000000 w F *UND* 0000000000000000 __pthread_key_create@@GLIBC_2.2.5
Shared library loaded by static binary
The programs that would introduce the external parallelism would also load pthread and enable the weak symbol in the library too. However, if the loading program has compiled pthread statically, the dynamic loader has no way of knowing if pthread_create is used by the program and wouldn’t make the weak symbol in the loaded library available. If this happens, the assumption would be broken and shared_ptr would be behaving erronously.
I assume that this is also a very rare case and from a quick googling, I can see tons of problems caused by using dlopen in statically compiled binaries.
In conclusion, I’ll assume this is not a typical scenario and it is mostly safe.
Why not go further with the optimization efforts?
If a program can assume that all its threading is happening through pthread with runtime checks, its implementation can be adapted to also detect when more than a thread is running.
Speculating, pthread could be updating a global count with the amount of running threads whenever threads are created, (un)suspended, or canceled. As far as I can think about it, the check doesn’t have to be atomic because when there is only one thread creating another one, the count doesn’t have to be atomic (from 0 to 1). Then when it’s suspending other threads, it can suspend it and later decrement the count. By the time the count is synchronized with the other thread, there is only one active again.
Is this a missed optimization opportunity?, probably not… However, the C++ standard is quite clear about the atomic operations in the libraries:
Library Wide Requirements - (2) Requirements specified in terms of interactions between threads do not apply to programs having only a single thread of execution.
Other C++ implementations
After my adventure with libstdc++, I decided to check VisualC++ and libcxx ones.
Libcxx has a compilation check with a macro to disable threads completely by the flag _LIBCPP_HAS_NO_THREADS. If it is set, all atomic operations will fallback to non-atomic ones. There is more information in the documentation.
VisualC++ doesn’t have its source code available, but from disassembling shared_ptr::operator=, I can see that the increment is only atomic and there is no runtime check to fall-back into a non-atomic one. It’s unclear to me if other versions provide them.
De-optimizing the micro-benchmark
This was an easy step, I just referenced pthread_create in the program and the reference count became atomic again.
Although uninteresting to the topic of the blog post, after the modifications, both programs performed very similarly in the benchmarks.
Add this optimization to Rust!
Not so fast! Arc actually means Atomic Reference Counted so it would be a plain lie if it hadn’t use atomic operations on the reference count.
Furthermore, Rust’s std offers both Rc and Arc which share similar APIs so they can be used interchangeably whenever necessary and the type system would get your back if you had sent Rc between tasks due to it being !Send (not send).
Conclusion
This was another failed case of micro-benchmarking. Optimizations go beyond your simple -O3. In this case, I didn’t know that the libstdc++ was changing its behaviour depending on if pthread_create was imported by the program or not.
While I’m probably not going to spend any more time on this, I’ve found a personally unknown thing about C++ standard library (GNU) and wanted to document it because it was interesting to track down.
Unfortunately, I cannot conclude if shared_ptr<T> behaviour is completely safe in uncommon environments.
Also, my teammates should be preparing themselves for all my new weakref optimizations that I’m introducing in my code…
Thanks for reading.
- Follow me on Twitter: @snfernandez
- Contact me at Gmail: sebanfernandez
- Secure is better: GPG Key